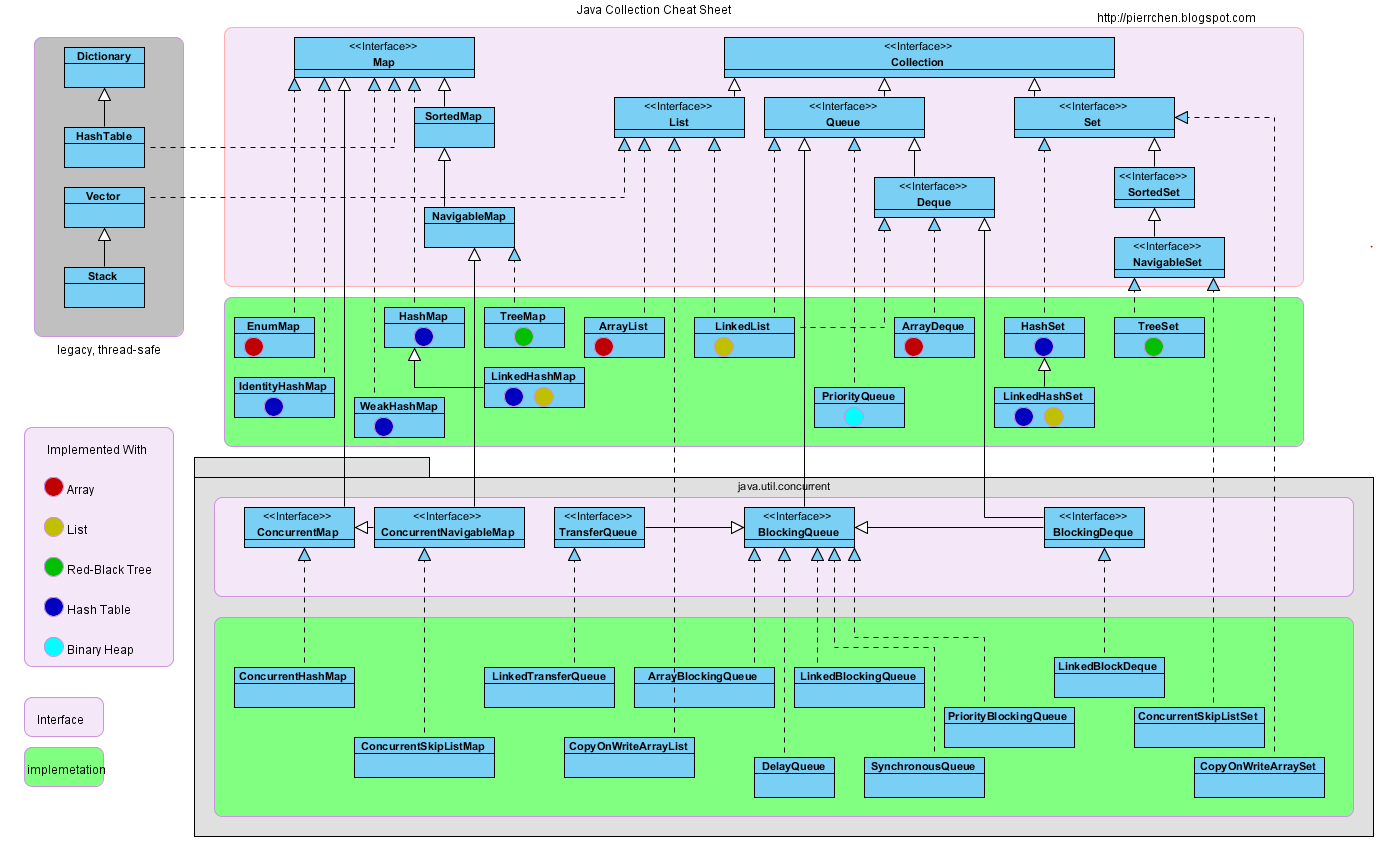
介绍
容器,就是可以容纳其他Java对象的对象。*Java Collections Framework(JCF)*为Java开发者提供了通用的容器,其始于JDK 1.2,优点是:
- 降低编程难度
- 提高程序性能
- 提高API间的互操作性
- 降低学习难度
- 降低设计和实现相关API的难度
- 增加程序的重用性
Java容器里只能放对象,对于基本类型(int, long, float, double等),需要将其包装成对象类型后(Integer, Long, Float, Double等)才能放到容器里。很多时候拆包装和解包装能够自动完成。这虽然会导致额外的性能和空间开销,但简化了设计和编程。
Collection
Set
Set集合是无序集合,集合中的元素不可以重复,访问集合中的元素只能根据元素本身来访问(也是集合里元素不允许重复的原因)
TreeSet
基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
优点
缺点
HashSet
基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。 HashSet和HashMap_有着相同的实现,前者仅仅是对后者做了一层包装,也就是说_HashSet_里面有一个_HashMap(适配器模式)。 请参考HashMap
LinkedHashSet
具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。
LinkedHashSet_和HashMap_有着相同的实现,前者仅仅是对后者做了一层包装,也就是说_HashSet_里面有一个_HashMap_(适配器模式)。 请参考LinkedHashMap
List
List集合是有序集合,集合中的元素可以重复,访问集合中的元素可以根据元素的索引来访问。
ArrayList
基于动态数组实现,支持随机访问,非线程安全的
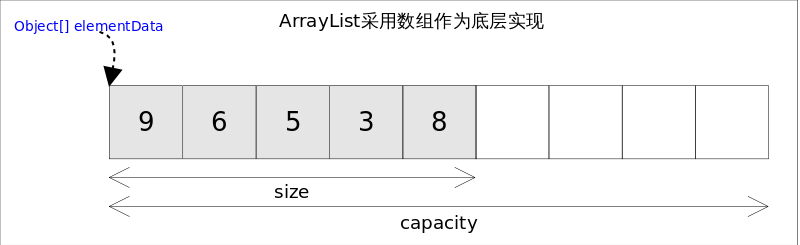
优点
- ArrayList底层是以数组实现,是一种随机访问模式,再加上它实现了RandomAccess接口,因此在执行get方法的时候很快。
- 遍历最大的优势在于内存的连续性,CPU的内部缓存结构会缓存连续的内存片段,可以大幅降低读取内存的性能开销。
缺点
- 数组里面(除了末尾)插入和删除元素效率不高,因为需要移动大量的元素
- ArrayList在小于扩容容量的情况下,其实增加操作效率非常高,在涉及扩容的情况下,添加操作效率确实低,删除操作需要移位拷贝。
- 同时因为ArrayList中增加(扩容)或者删除元素要调用System.arrayCopy()这种效率很低的方法进行处理,所以遇到数据量略大 或者 需要频繁插入和删除操作的时候,效率就比较低了,如果遇到上述的场景,那么就需要使用LinkedList来代替因为ArrayList的优点在于构造好数组后,频繁的访问元素的效率非常高。
扩容策略
ArrayList变为原来的1.5倍,如果1.5倍以后长度还是不够,就会设置长度为所需的空间。
Vector
Vector的优缺点与ArrayList基本一致,但Vector是线程安全的
扩容策略
默认容量大小是10,若容量增加系数 >0,则将容量的值增加“容量增加系数”;否则,将容量大小增加2倍
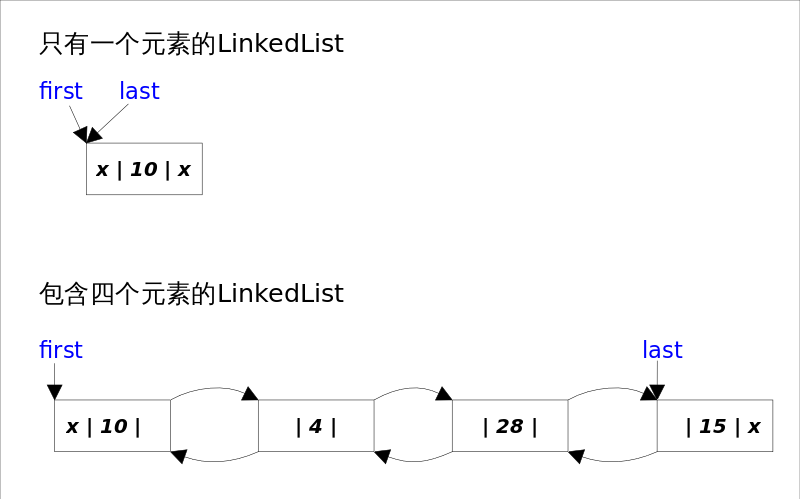
LinkedList
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(它是个接口名字)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
_LinkedList_的实现方式决定了所有跟下标相关的操作都是线性时间,而在首段或者末尾删除元素只需要常数时间。_LinkedList_是线程不安全的
Queue
单端队列,只能从一端插入元素,另一端删除元素,实现上一般遵循 先进先出(FIFO) 规则。
PriorityQueue
基于堆结构实现,可以用它来实现优先队列。
优先队列的作用是能保证每次取出的元素都是队列中权值最小的(Java的优先队列每次取最小元素,C++的优先队列每次取最大元素)。这里牵涉到了大小关系,元素大小的评判可以通过元素本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator,类似于C++的仿函数)。
Java中_PriorityQueue_实现了_Queue_接口,不允许放入null元素;其通过堆实现,具体说是通过完全二叉树(complete binary tree)实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为_PriorityQueue_的底层实现。
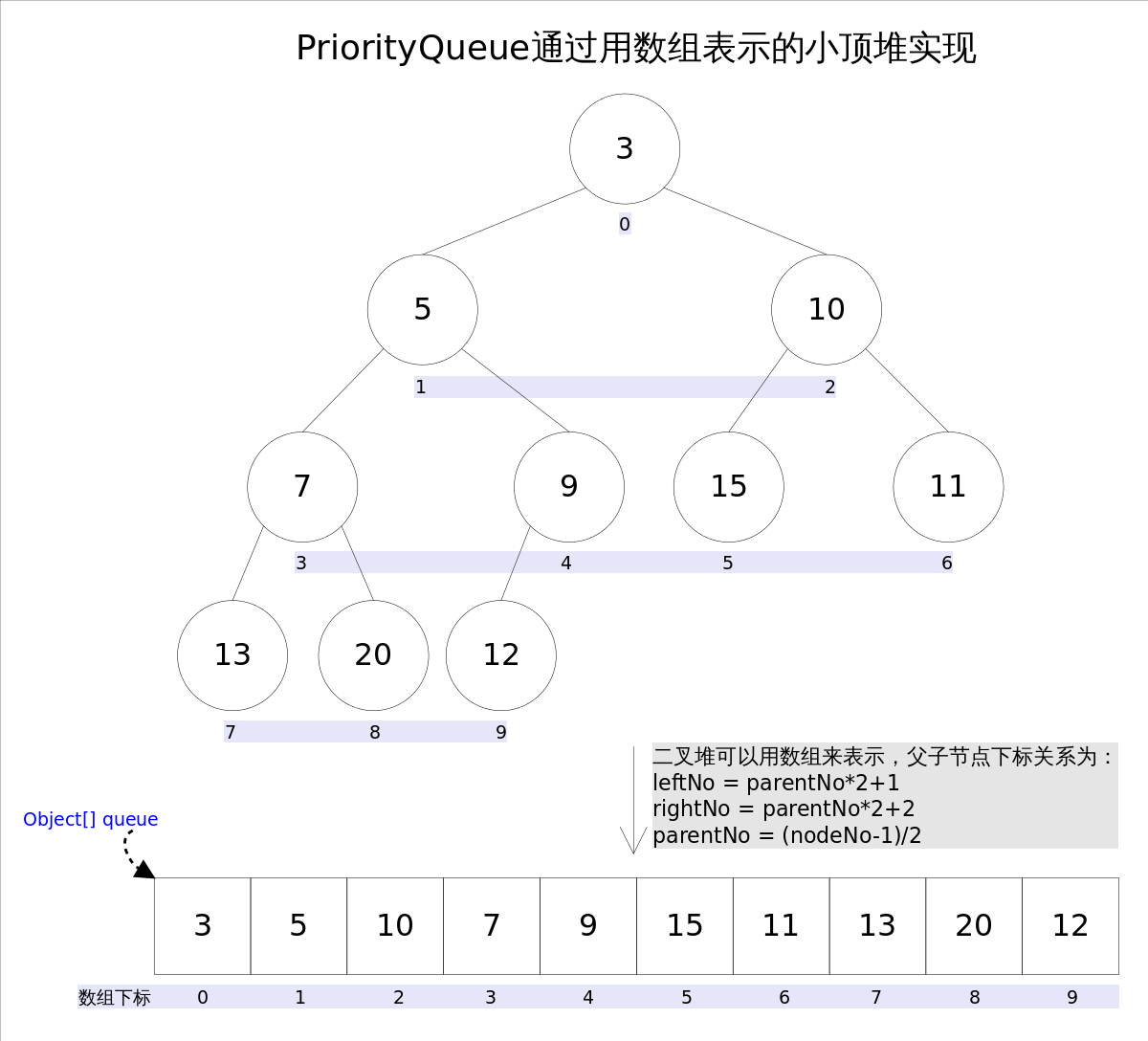 上图中我们给每个元素按照层序遍历的方式进行了编号,如果你足够细心,会发现父节点和子节点的编号是有联系的,更确切的说父子节点的编号之间有如下关系:
leftNo = parentNo2+1
rightNo = parentNo2+2
parentNo = (nodeNo-1)/2
通过上述三个公式,可以轻易计算出某个节点的父节点以及子节点的下标。这也就是为什么可以直接用数组来存储堆的原因。
上图中我们给每个元素按照层序遍历的方式进行了编号,如果你足够细心,会发现父节点和子节点的编号是有联系的,更确切的说父子节点的编号之间有如下关系:
leftNo = parentNo2+1
rightNo = parentNo2+2
parentNo = (nodeNo-1)/2
通过上述三个公式,可以轻易计算出某个节点的父节点以及子节点的下标。这也就是为什么可以直接用数组来存储堆的原因。
Deque
是双端队列,在队列的两端均可以插入或删除元素。 ArrayDeque和LinkedList都实现了Deque
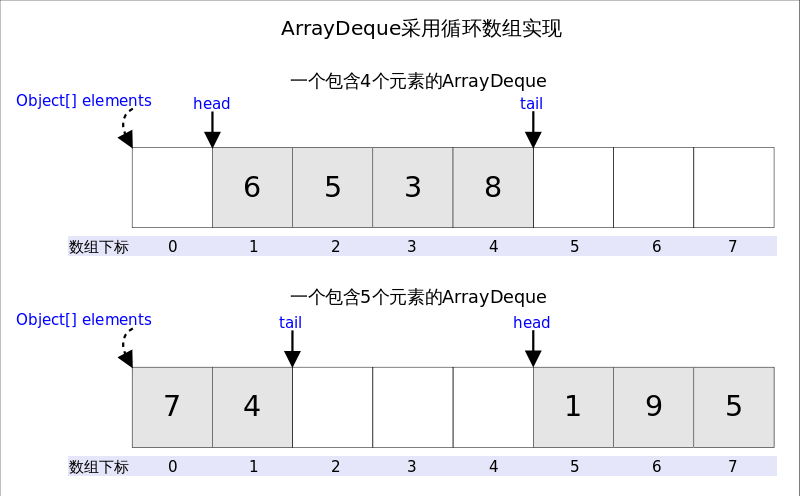
ArrayDeque
从名字可以看出_ArrayDeque_底层通过数组实现,为了满足可以同时在数组两端插入或删除元素的需求,该数组还必须是循环的,即循环数组(circular array),也就是说数组的任何一点都可能被看作起点或者终点。_ArrayDeque_是非线程安全的(not thread-safe),当多个线程同时使用的时候,需要程序员手动同步;另外,该容器不允许放入null元素。
Map
TreeMap
基于红黑树实现。
HashMap
基于哈希表实现。
_HashMap_实现了_Map_接口,即允许放入key为null的元素,也允许插入value为null的元素;除该类未实现同步外,其余跟Hashtable大致相同;跟_TreeMap_不同,该容器不保证元素顺序,根据需要该容器可能会对元素重新哈希,元素的顺序也会被重新打散,因此不同时间迭代同一个_HashMap_的顺序可能会不同。 根据对冲突的处理方式不同,哈希表有两种实现方式,一种开放地址方式(Open addressing),另一种是冲突链表方式(Separate chaining with linked lists)。
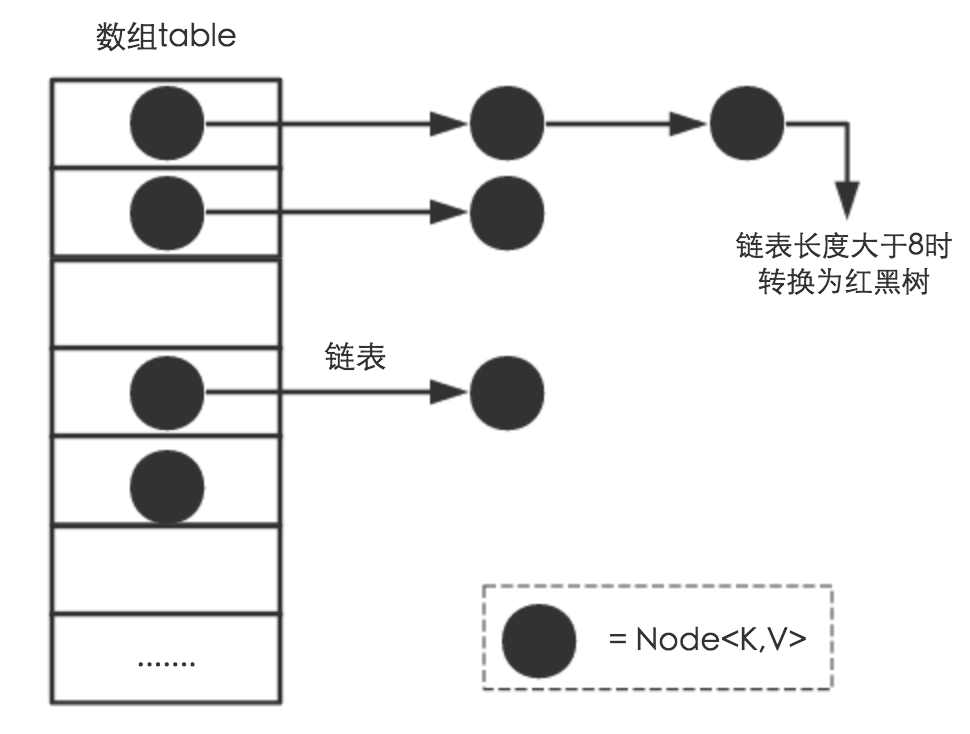
初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacityload_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数 将对象放入到_HashMap_或_HashSet_中时,有两个方法需要特别关心: hashCode()和equals()。hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。所以,如果要将自定义的对象放入到HashMap或HashSet中,需要@Override*hashCode()和equals()方法。
扩容策略
每次扩容后,容量为原来的 2 倍,并进行数据迁移
HashTable
和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
LinkedHashMap
使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
带着问题思考
1.ArrayList与LinkedList的区别是什么?
- ArrayList 底层使用的是Object数组,初始化时就会指向的会是一个static修饰的空数组,数组长度一开始为0,插入第一个元素时数组长度会初始化为10,之后每次数组空间不够进行扩容时都是增加为原来的1.5倍。ArrayList的空间浪费主要体现在在list列表的结尾会预留一定的容量空间(为了避免添加元素时,数组空间不够频繁申请内存),而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放后继指针next和前驱指针pre以及数据)
- LinkedList 底层使用的数据结构是双向链表,每个节点保存了指向前驱节点和后继结点的指针。初始化时,不执行任何操作,添加第一个元素时,再去构造链表中的节点。
2.怎么使ArrayList,LinkedList变成线程安全的呢?
- 使用Vector 读写均加锁
- Collections.SynchronizedList 使用sync代码块装饰传入List的读写操作(读写均加锁)
- CopyOnWriteArrayList 写操作每一次均copy一个数组,读操作不加锁(写加锁性能低,读不加锁性能极高) ,但是无法提供实时一致性。写时复制(Copy-On-Write)容器的线程安全性在于,只要正确的发布一个事实不可变的对象,那么在访问该对象时就不需要进一步的同步。在每次修改时,都会创建并重新发布一个新的容器副本,从而实现可变性。 但是显然,每次修改容器使都会复制底层数组,这需要一定的开销,特别是当容器的规模较大时。 仅当迭代操作远远多于修改操作时,才应该使用"写时复制"容器
3.ArrayDeque与LinkedList的区别?
- ArrayDeque 是基于可变长的数组和双指针来实现,而 LinkedList 则通过链表来实现。
- ArrayDeque 不支持存储 NULL 数据,但 LinkedList 支持。
- ArrayDeque 是在 JDK1.6 才被引入的,而LinkedList 早在 JDK1.2 时就已经存在。
- ArrayDeque 插入时可能存在扩容过程, 不过均摊后的插入操作依然为 O(1)。虽然 LinkedList 不需要扩容,但是每次插入数据时均需要申请新的堆空间,均摊性能相比更慢。
从性能的角度上,选用 ArrayDeque 来实现队列要比 LinkedList 更好。此外,ArrayDeque 也可以用于实现栈