AOF日志
AOF 它是写后日志,“写后”的意思是 Redis 是先执行命令,把数据写入内存,然后才记录日志,如下图所示:
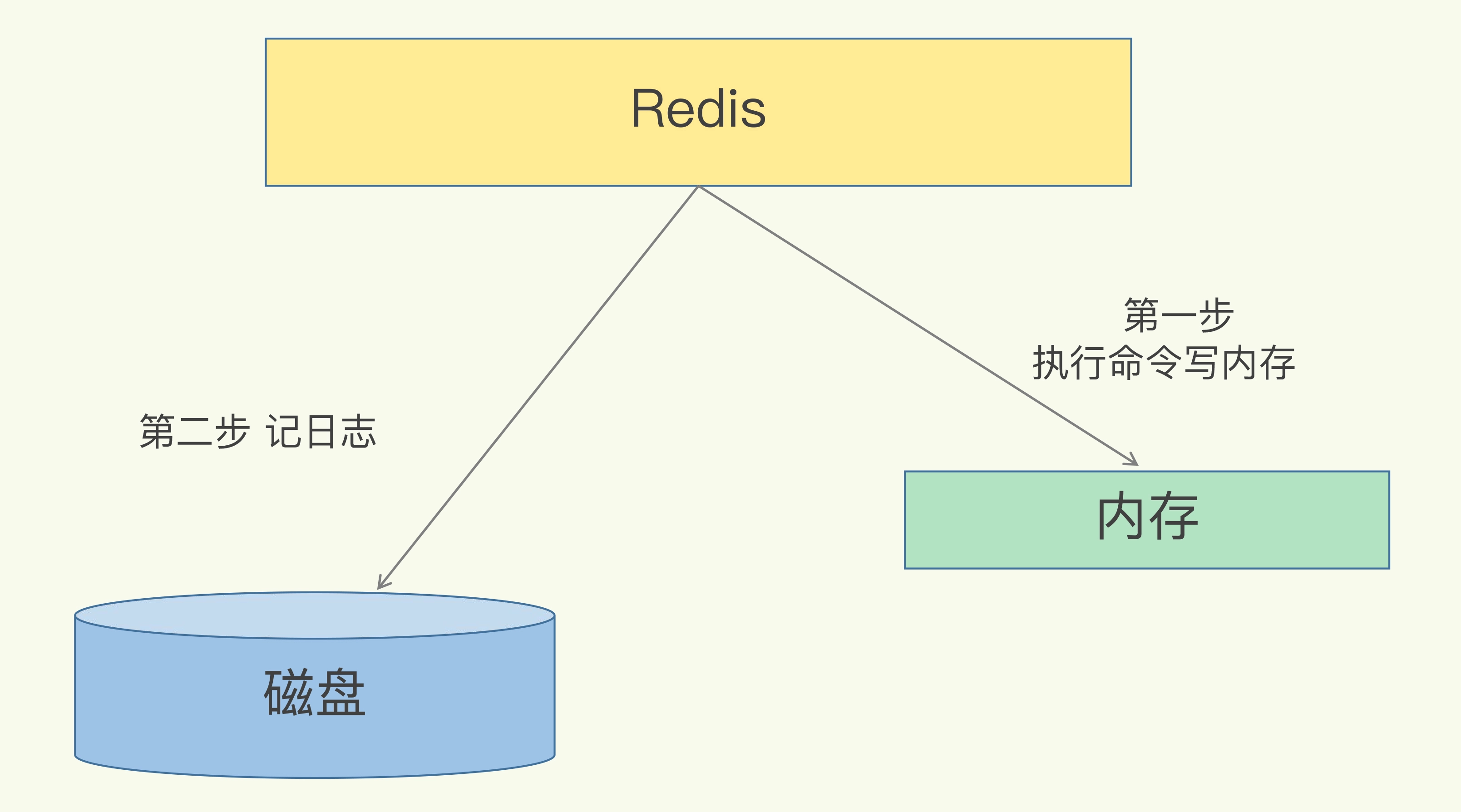
优点
- 可以避免出现记录错误命令的情况。
- 它是在命令执行后才记录日志,所以不会阻塞当前的写操作。
缺点
- 如果刚执行完一个命令,还没有来得及记日志就宕机了,那么这个命令和相应的数据就有丢失的风险。如果此时 Redis 是用作缓存,还可以从后端数据库重新读入数据进行恢复,但是,如果 Redis 是直接用作数据库的话,此时,因为命令没有记入日志,所以就无法用日志进行恢复了。
- AOF 虽然避免了对当前命令的阻塞,但可能会给下一个操作带来阻塞风险。这是因为,AOF 日志也是在主线程中执行的,如果在把日志文件写入磁盘时,磁盘写压力大,就会导致写盘很慢,进而导致后续的操作也无法执行了。
写回策略
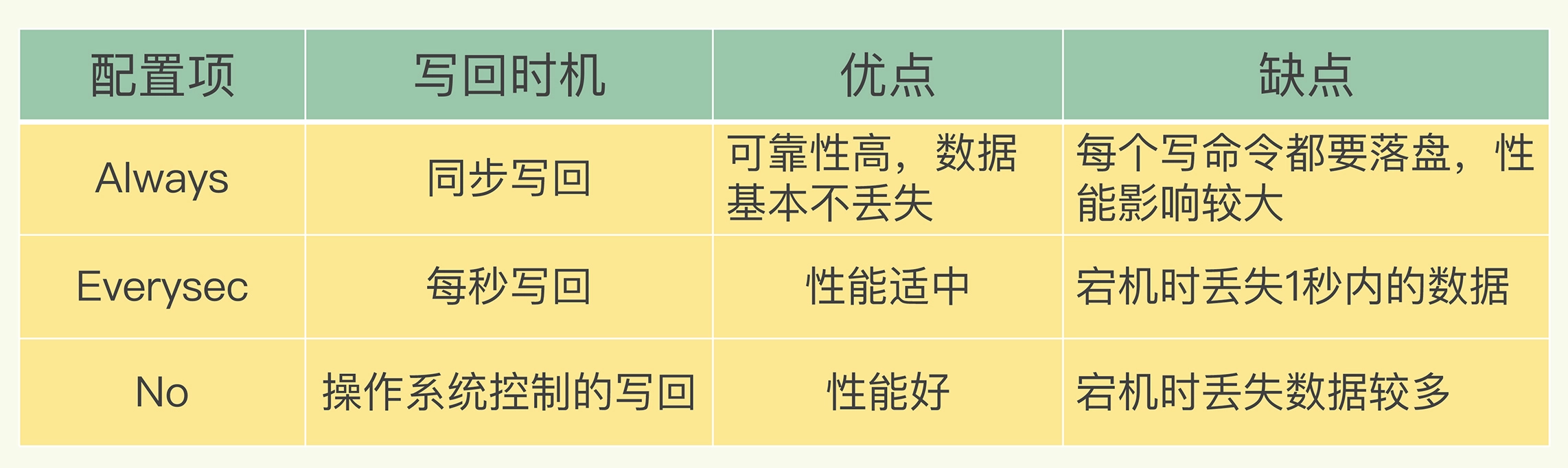
- Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
- Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
- No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
 按照系统的性能需求选定了写回策略,并不是“高枕无忧”了。毕竟,AOF 是以文件的形式在记录接收到的所有写命令。随着接收的写命令越来越多,AOF 文件会越来越大。这也就意味着,我们一定要小心 AOF 文件过大带来的性能问题。
按照系统的性能需求选定了写回策略,并不是“高枕无忧”了。毕竟,AOF 是以文件的形式在记录接收到的所有写命令。随着接收的写命令越来越多,AOF 文件会越来越大。这也就意味着,我们一定要小心 AOF 文件过大带来的性能问题。
性能问题
- 一是,文件系统本身对文件大小有限制,无法保存过大的文件;
- 二是,如果文件太大,之后再往里面追加命令记录的话,效率也会变低;
- 三是,如果发生宕机,AOF 中记录的命令要一个个被重新执行,用于故障恢复,如果日志文件太大,整个恢复过程就会非常缓慢,这就会影响到 Redis 的正常使用。
注意事项
日志文件太大了怎么办?
简单来说,AOF 重写机制就是在重写时,Redis 根据数据库的现状创建一个新的 AOF 文件,也就是说,读取数据库中的所有键值对,然后对每一个键值对用一条命令记录它的写入。比如说,当读取了键值对“testkey”: “testvalue”之后,重写机制会记录 set testkey testvalue 这条命令。这样,当需要恢复时,可以重新执行该命令,实现“testkey”: “testvalue”的写入。
为什么重写机制可以把日志文件变小呢? 实际上,重写机制具有“多变一”功能。所谓的“多变一”,也就是说,旧日志文件中的多条命令,在重写后的新日志中变成了一条命令。
我们知道,AOF 文件是以追加的方式,逐一记录接收到的写命令的。当一个键值对被多条写命令反复修改时,AOF 文件会记录相应的多条命令。但是,在重写的时候,是根据这个键值对当前的最新状态,为它生成对应的写入命令。这样一来,一个键值对在重写日志中只用一条命令就行了,而且,在日志恢复时,只用执行这条命令,就可以直接完成这个键值对的写入了。
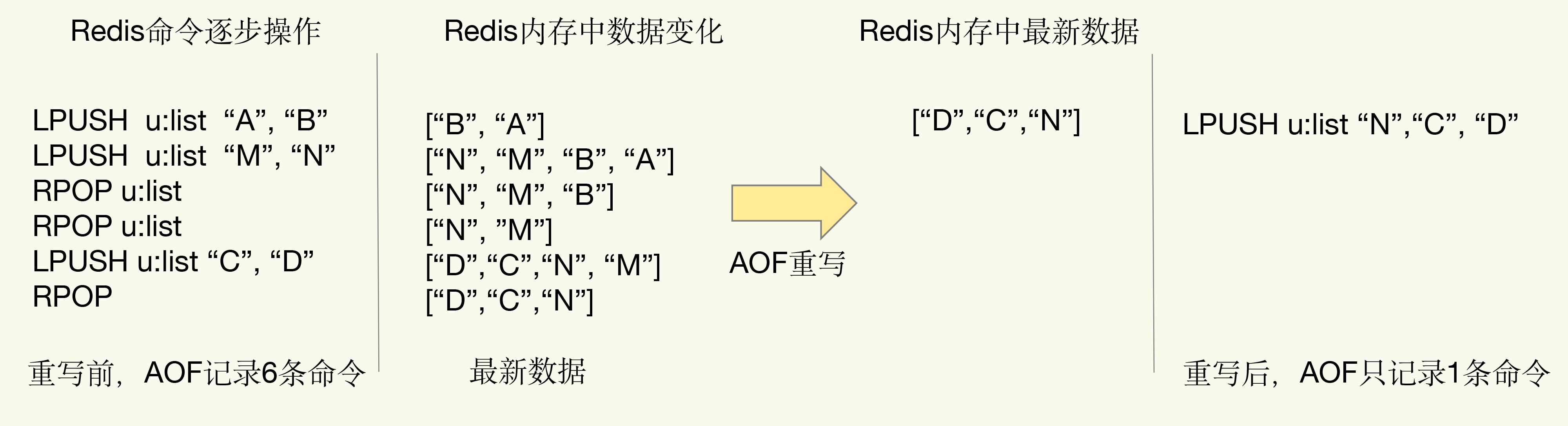 当我们对一个列表先后做了 6 次修改操作后,列表的最后状态是[“D”, “C”, “N”],此时,只用 LPUSH u:list “N”, “C”, “D"这一条命令就能实现该数据的恢复,这就节省了五条命令的空间。对于被修改过成百上千次的键值对来说,重写能节省的空间当然就更大了。不过,虽然 AOF 重写后,日志文件会缩小,但是,要把整个数据库的最新数据的操作日志都写回磁盘,仍然是一个非常耗时的过程。这时,我们就要继续关注另一个问题了:重写会不会阻塞主线程?
当我们对一个列表先后做了 6 次修改操作后,列表的最后状态是[“D”, “C”, “N”],此时,只用 LPUSH u:list “N”, “C”, “D"这一条命令就能实现该数据的恢复,这就节省了五条命令的空间。对于被修改过成百上千次的键值对来说,重写能节省的空间当然就更大了。不过,虽然 AOF 重写后,日志文件会缩小,但是,要把整个数据库的最新数据的操作日志都写回磁盘,仍然是一个非常耗时的过程。这时,我们就要继续关注另一个问题了:重写会不会阻塞主线程?
AOF 重写会阻塞吗?
和 AOF 日志由主线程写回不同,重写过程是由后台子进程 bgrewriteaof 来完成的,这也是为了避免阻塞主线程,导致数据库性能下降。
我把重写的过程总结为“一个拷贝,两处日志”。
“一个拷贝”就是指,每次执行重写时,主线程 fork 出后台的 bgrewriteaof 子进程。此时,fork 会把主线程的内存拷贝一份给 bgrewriteaof 子进程,这里面就包含了数据库的最新数据。然后,bgrewriteaof 子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志。
“两处日志”又是什么呢?
因为主线程未阻塞,仍然可以处理新来的操作。此时,如果有写操作,第一处日志就是指正在使用的 AOF 日志,Redis 会把这个操作写到它的缓冲区。这样一来,即使宕机了,这个 AOF 日志的操作仍然是齐全的,可以用于恢复。
而第二处日志,就是指新的 AOF 重写日志。这个操作也会被写到重写日志的缓冲区。这样,重写日志也不会丢失最新的操作。等到拷贝数据的所有操作记录重写完成后,重写日志记录的这些最新操作也会写入新的 AOF 文件,以保证数据库最新状态的记录。此时,我们就可以用新的 AOF 文件替代旧文件了。
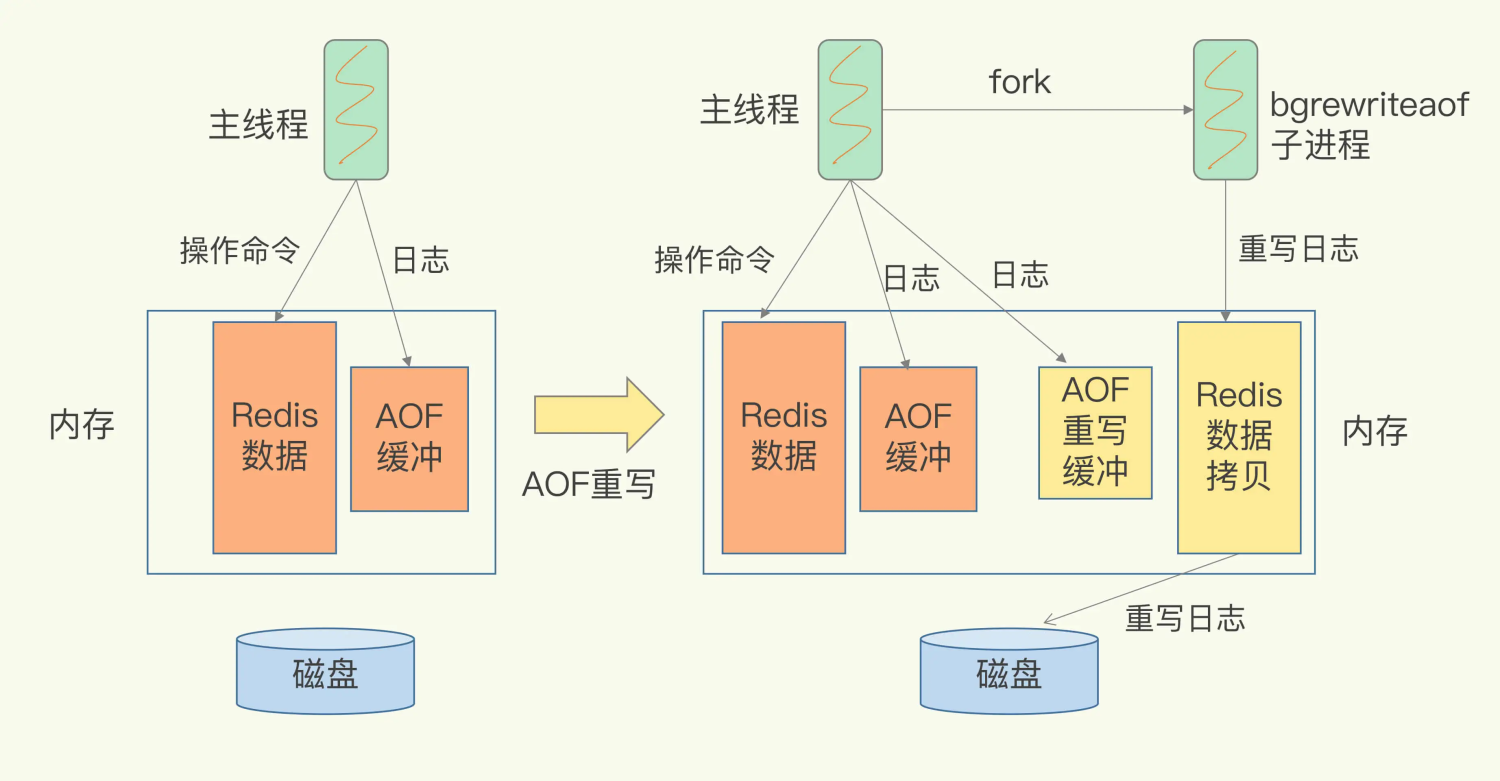 总结来说,每次 AOF 重写时,Redis 会先执行一个内存拷贝,用于重写;然后,使用两个日志保证在重写过程中,新写入的数据不会丢失。而且,因为 Redis 采用额外的线程进行数据重写,所以,这个过程并不会阻塞主线程。
总结来说,每次 AOF 重写时,Redis 会先执行一个内存拷贝,用于重写;然后,使用两个日志保证在重写过程中,新写入的数据不会丢失。而且,因为 Redis 采用额外的线程进行数据重写,所以,这个过程并不会阻塞主线程。
RDB内存快照
所谓内存快照,就是指内存中的数据在某一个时刻的状态记录
优点
- 生成RDB 文件的时候,redis 主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO 操作。
- RDB 在恢复大数据集时的速度比AOF 的恢复速度要快。
缺点
- RDB 方式数据没办法做到实时持久化/秒级持久化。因为bgsave 每次运行都要执行fork 操作创建子进程,频繁执行成本过高。
- 在一定间隔时间做一次备份,所以如果redis 意外down 掉的话,就会丢失最后一次快照之后的所有修改(数据有丢失)。
对 Redis 来说,它实现类似照片记录效果的方式,就是把某一时刻的状态以文件的形式写到磁盘上,也就是快照。这样一来,即使宕机,快照文件也不会丢失,数据的可靠性也就得到了保证。这个快照文件就称为 RDB 文件,其中,RDB 就是 Redis DataBase 的缩写。
和 AOF 相比,RDB 记录的是某一时刻的数据,并不是操作,所以,在做数据恢复时,我们可以直接把 RDB 文件读入内存,很快地完成恢复。但我们还要考虑两个关键问题:
- 对哪些数据做快照?这关系到快照的执行效率问题;
- 做快照时,数据还能被增删改吗?这关系到 Redis 是否被阻塞,能否同时正常处理请求。
注意事项
对哪些数据做快照?
Redis 的数据都在内存中,为了提供所有数据的可靠性保证,它执行的是全量快照,也就是说,把内存中的所有数据都记录到磁盘中,同样,给内存的全量数据做快照,把它们全部写入磁盘也会花费很多时间。而且,全量数据越多,RDB 文件就越大,往磁盘上写数据的时间开销就越大。 Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave。
- save:在主线程中执行,会导致阻塞;
- bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置。
快照时数据能修改吗?
bgsave 虽然可以避免阻塞。但是避免阻塞和正常处理写操作并不是一回事。此时,主线程的确没有阻塞,可以正常接收请求,但是,为了保证快照完整性,它只能处理读操作,因为不能修改正在执行快照的数据。
为了快照而暂停写操作,肯定是不能接受的。所以这个时候,Redis 就会借助操作系统提供的写时复制技术(Copy-On-Write, COW),在执行快照的同时,正常处理写操作。 简单来说,bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。
此时,如果主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 C),那么,这块数据就会被复制一份,生成该数据的副本(键值对 C’)。然后,主线程在这个数据副本上进行修改。同时,bgsave 子进程可以继续把原来的数据(键值对 C)写入 RDB 文件。
可以每秒做一次快照吗?
对于快照来说,所谓“连拍”就是指连续地做快照。这样一来,快照的间隔时间变得很短,即使某一时刻发生宕机了,因为上一时刻快照刚执行,丢失的数据也不会太多。但是,这其中的快照间隔时间就很关键了。
如下图所示,我们先在 T0 时刻做了一次快照,然后又在 T0+t 时刻做了一次快照,在这期间,数据块 5 和 9 被修改了。如果在 t 这段时间内,机器宕机了,那么,只能按照 T0 时刻的快照进行恢复。此时,数据块 5 和 9 的修改值因为没有快照记录,就无法恢复了。
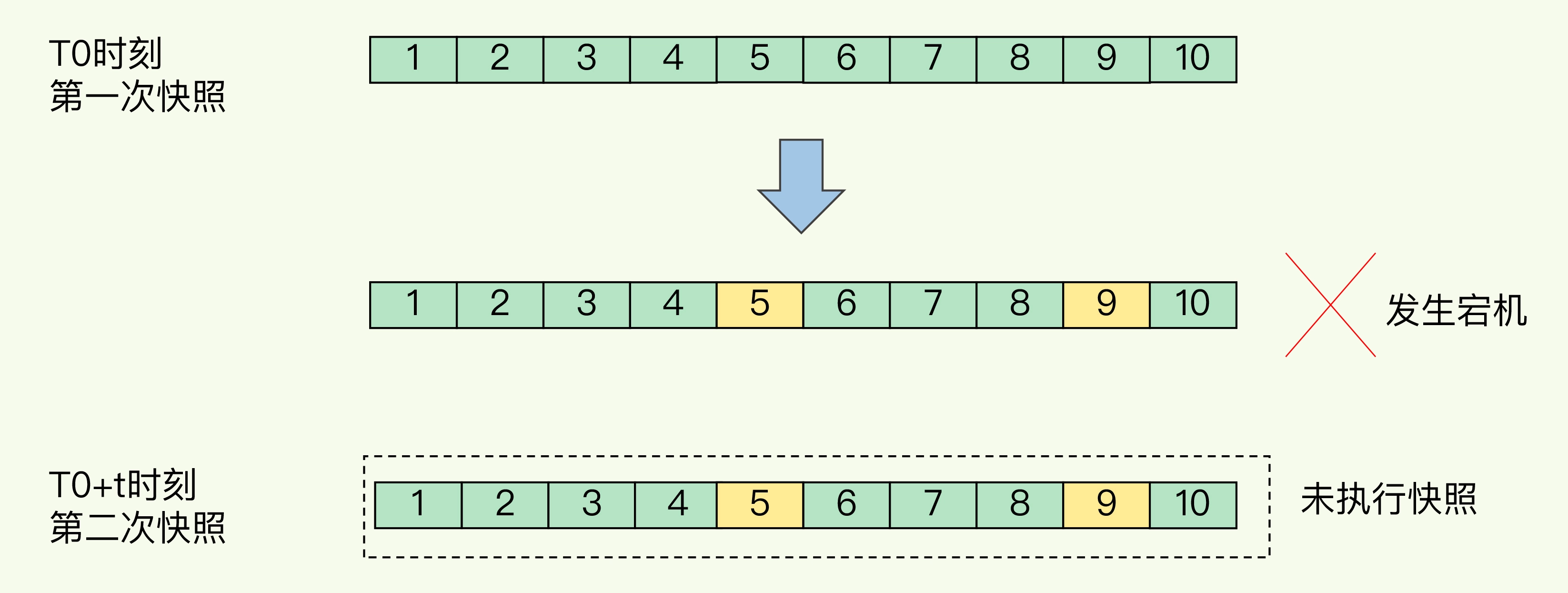 所以,要想尽可能恢复数据,t 值就要尽可能小,t 越小,就越像“连拍”。那么,t 值可以小到什么程度呢,比如说是不是可以每秒做一次快照?毕竟,每次快照都是由 bgsave 子进程在后台执行,也不会阻塞主线程。
所以,要想尽可能恢复数据,t 值就要尽可能小,t 越小,就越像“连拍”。那么,t 值可以小到什么程度呢,比如说是不是可以每秒做一次快照?毕竟,每次快照都是由 bgsave 子进程在后台执行,也不会阻塞主线程。
这种想法其实是错误的。虽然 bgsave 执行时不阻塞主线程,但是,如果频繁地执行全量快照,也会带来两方面的开销。
- 频繁将全量数据写入磁盘,会给磁盘带来很大压力,多个快照竞争有限的磁盘带宽,前一个快照还没有做完,后一个又开始做了,容易造成恶性循环。
- bgsave 子进程需要通过 fork 操作从主线程创建出来。虽然,子进程在创建后不会再阻塞主线程,但是,fork 这个创建过程本身会阻塞主线程,而且主线程的内存越大,阻塞时间越长。如果频繁 fork 出 bgsave 子进程,这就会频繁阻塞主线程了(所以,在 Redis 中如果有一个 bgsave 在运行,就不会再启动第二个 bgsave 子进程)。
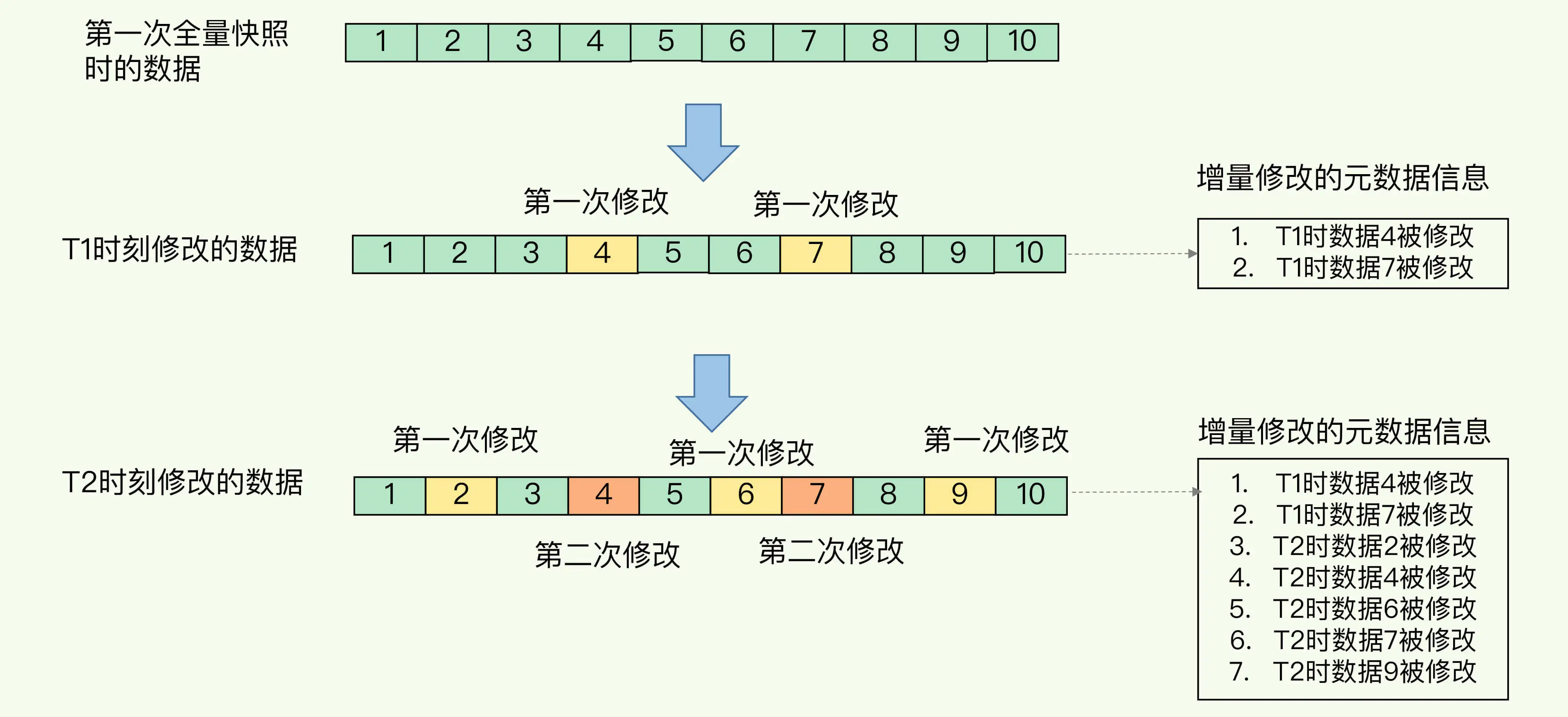
此时,我们可以做增量快照,但是,这么做的前提是,我们需要记住哪些数据被修改了,这会带来额外的空间开销问题。如下图所示:
二者区别
如果可以忍受一小段时间内数据的丢失,毫无疑问使用RDB 是最好的,定时生成RDB 快照(snapshot)非常便于进行数据库备份, 并且RDB 恢复数据集的速度也要比AOF 恢复的速度要快。 否则就使用AOF 重写。但是一般情况下建议不要单独使用某一种持久化机制,而是应该两种一起用,在这种情况下,当redis 重启的时候会优先载入AOF 文件来恢复原始的数据,因为在通常情况下AOF 文件保存的数据集要比RDB 文件保存的数据集要完整。
AOF+RDB混合使用
内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。 这样一来,快照不用很频繁地执行,这就避免了频繁 fork 对主线程的影响。而且,AOF 日志也只用记录两次快照间的操作,也就是说,不需要记录所有操作了,因此,就不会出现文件过大的情况了,也可以避免重写开销。
如下图所示,T1 和 T2 时刻的修改,用 AOF 日志记录,等到第二次做全量快照时,就可以清空 AOF 日志,因为此时的修改都已经记录到快照中了,恢复时就不再用日志了。
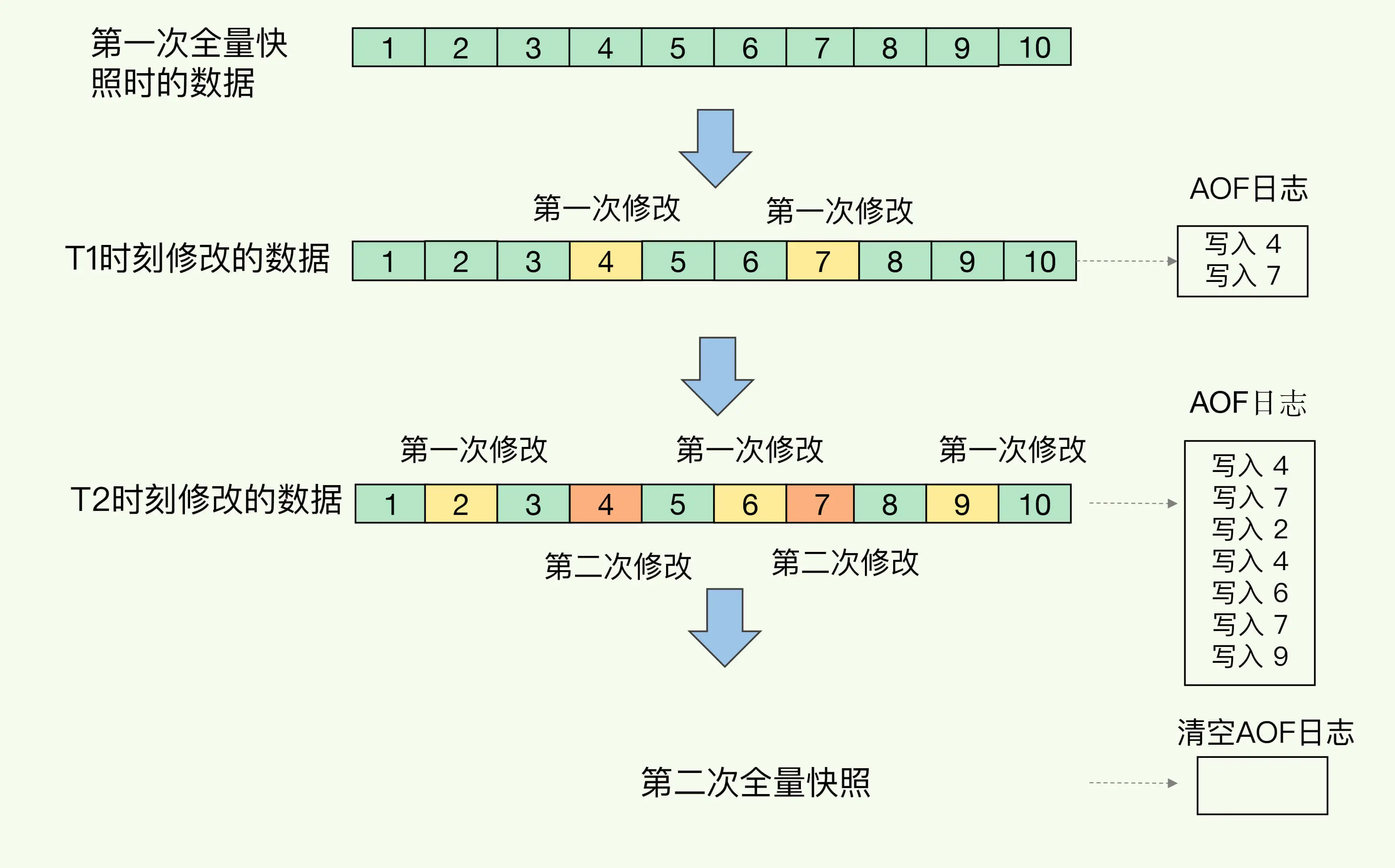 这个方法既能享受到 RDB 文件快速恢复的好处,又能享受到 AOF 只记录操作命令的简单优势,颇有点“鱼和熊掌可以兼得”的感觉
这个方法既能享受到 RDB 文件快速恢复的好处,又能享受到 AOF 只记录操作命令的简单优势,颇有点“鱼和熊掌可以兼得”的感觉