基本介绍
基础数据结构
String
你可以把String类型用于存储某个标志位,某个计数器,甚至狠一点,序列化之后的JSON字符串都行,其单个key限制为512M
List
- 当作普通列表存储数据(类似于Java的ArrayList)
- 用做异步队列
Hash
如果除了需要存储键值数据,还想单独对某个字段进行操作,使用 Hash 就非常方便
Set
如果想得到一个不重复的集合,就可以使用 Set,而且它还可以做并集、差集和交集运算;
Sorted Set
如果想实现一个带权重的评论、排行榜列表,那么,Sorted Set 就能满足你。
扩展数据结构
HyperLogLog
版本2.8.9以后 适用于大数据量的基数统计,但是它也存在局限性,它只能够实现统计基数的数量,但无法知道具体的原数据是什么。如果需要原数据的话,我们可以将 Bitmap 和 HyperLogLog 配合使用,例如在统计网站UV时,使用Bitmap 标识哪些用户属于活跃用户,使用 HyperLogLog 实现基数统计。
Bitmap
版本2.2以后 是以 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。其中每一个bit都只能是0或1,所以通常用来表示一个对应于数组下标的数据是否存在 主要用于对 bit 位进行读写、计算、统计等操作。
GEO
版本3.2以后 主要用于存储地理位置信息,并可以对存储的信息进行一系列的计算操作。
Stream
版本5.0以后 实现了消息队列的功能,并且实现消息的持久化和主备复制功能
具体场景下
缓存雪崩
缓存雪崩是指大量的应用请求无法在 Redis 缓存中进行处理,紧接着,应用将大量请求发送到数据库层,导致数据库层的压力激增。
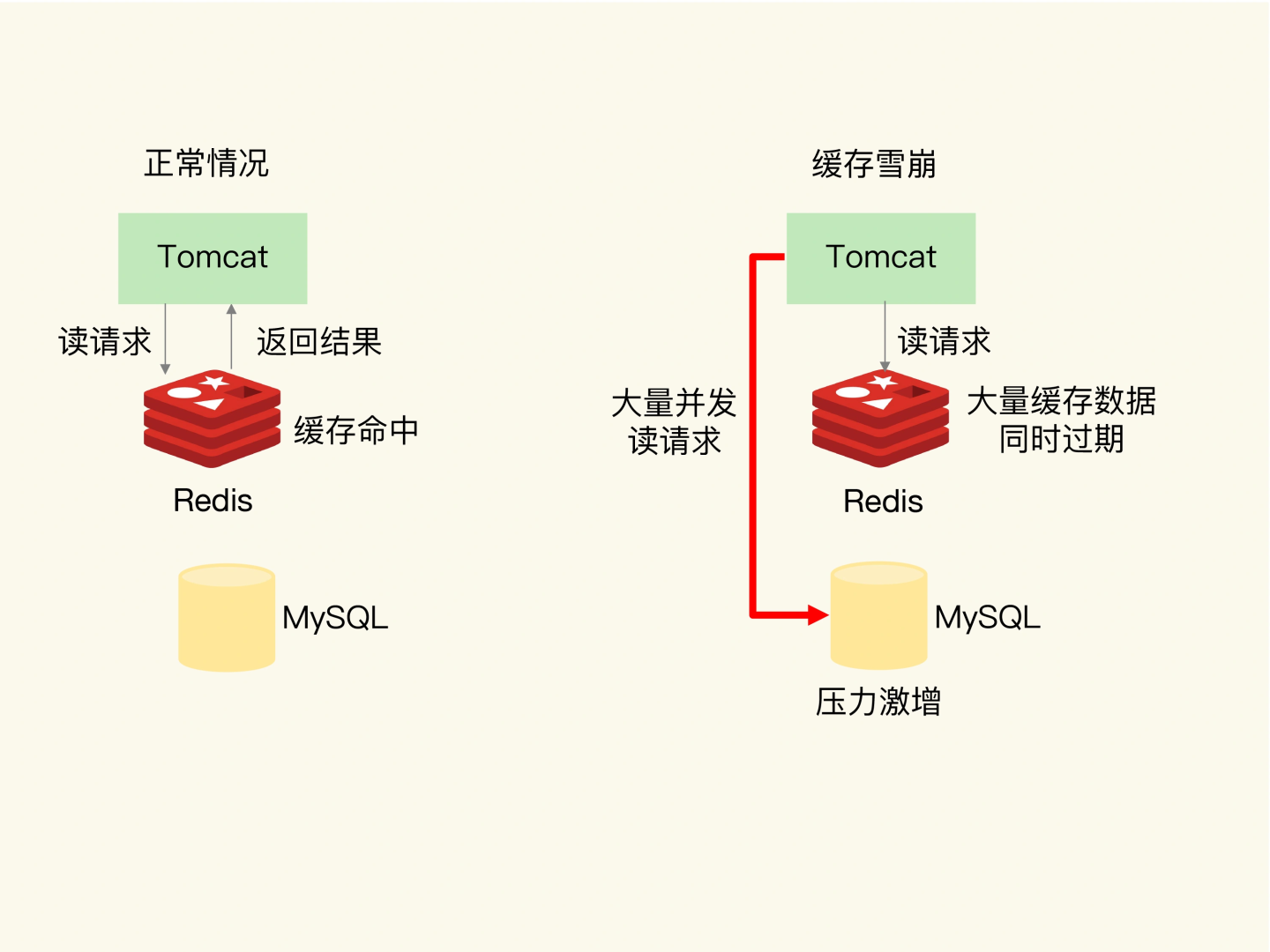
解决方案
- 将缓存失效时间分散开:比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
- 使用熔断机制。当流量到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
缓存击穿
缓存击穿是指,针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,紧接着,访问该数据的大量请求,一下子都发送到了后端数据库,导致了数据库压力激增,会影响数据库处理其他请求。
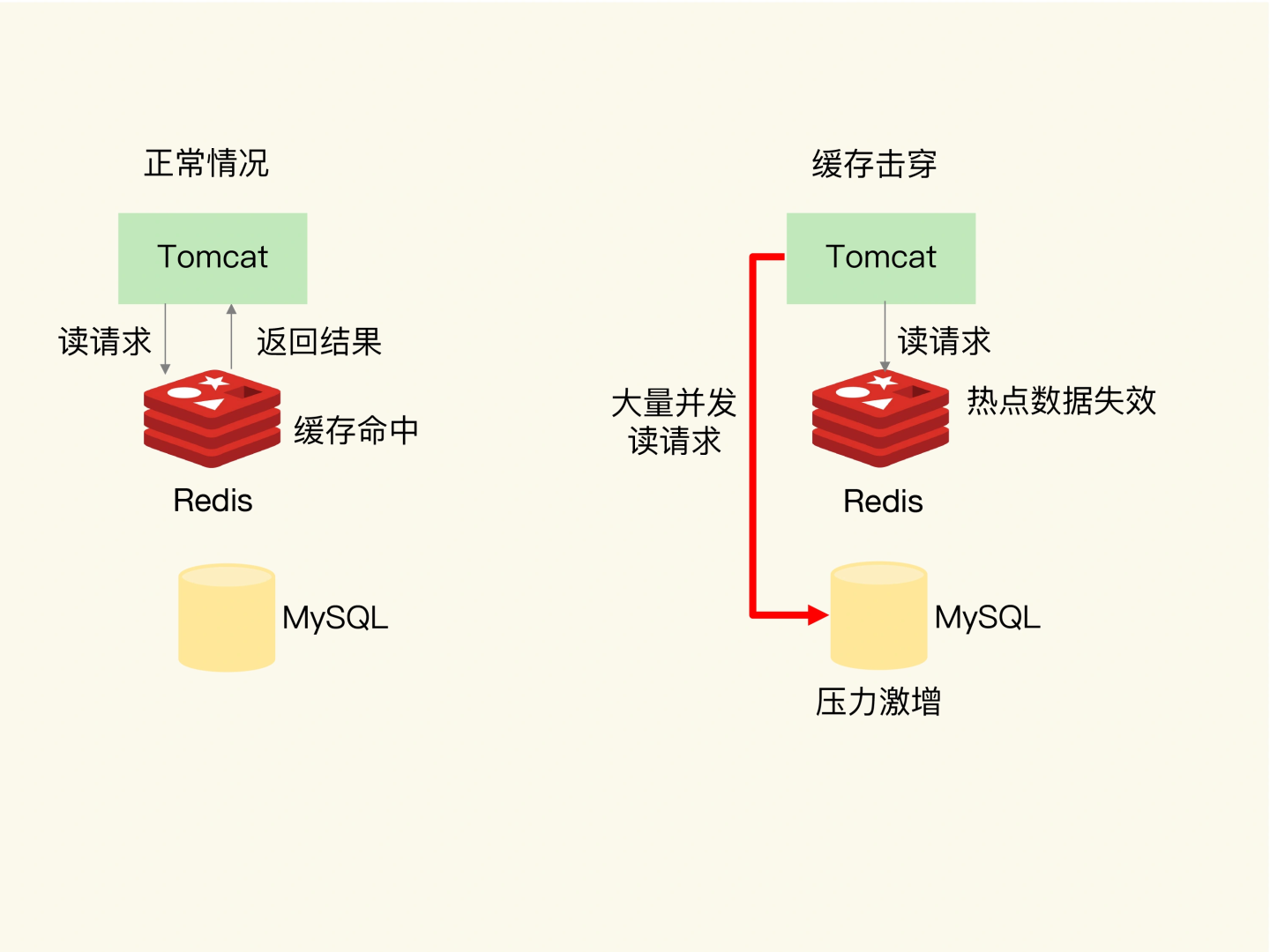
解决方案
- 预先设置热门数据:在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长
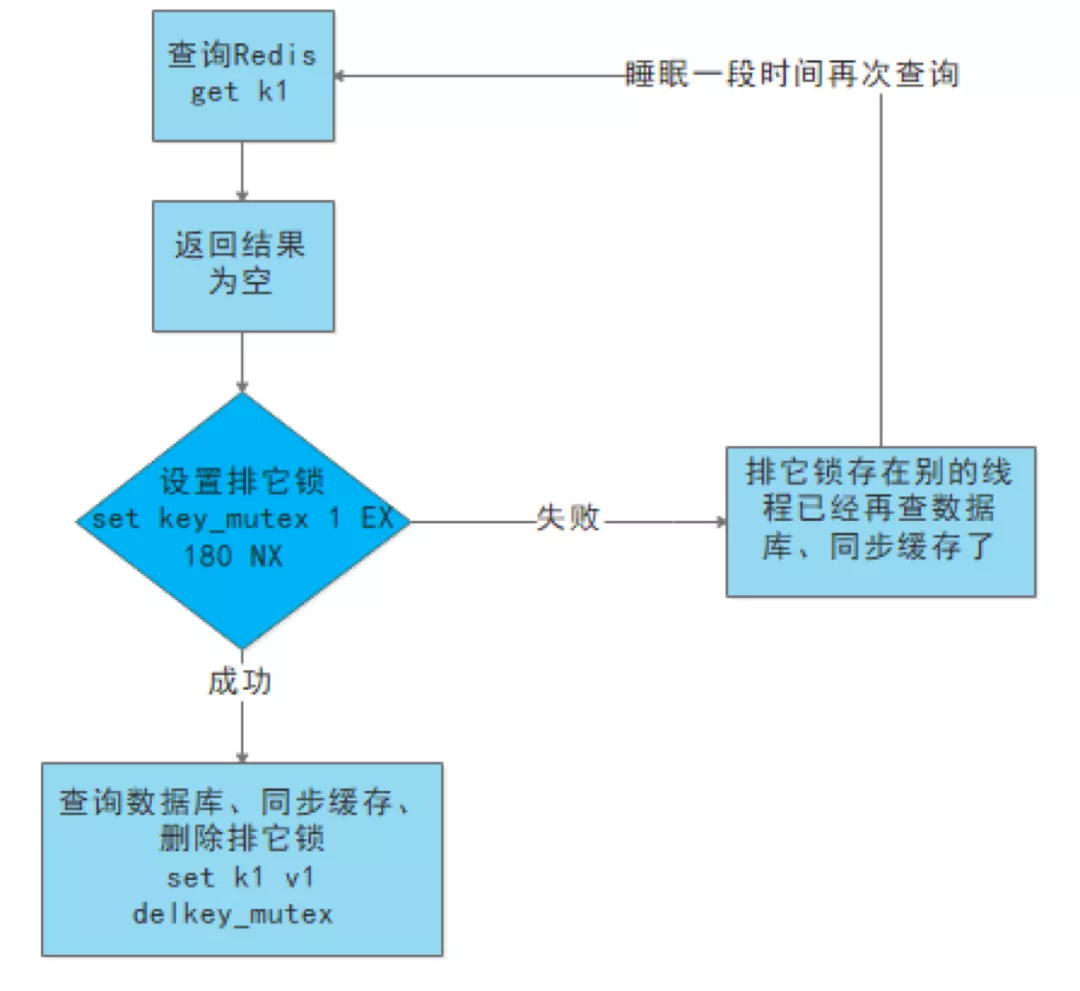
- 使用互斥锁: 就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db。先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)去set一个mutex key,当操作返回成功时,再进行load db的操作,并回设缓存,最后删除mutex key。当操作返回失败,证明有线程在load db,当前线程睡眠一段时间再重试整个get缓存的方法。
缓存穿透
缓存穿透是指要访问的数据既不在 Redis 缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。
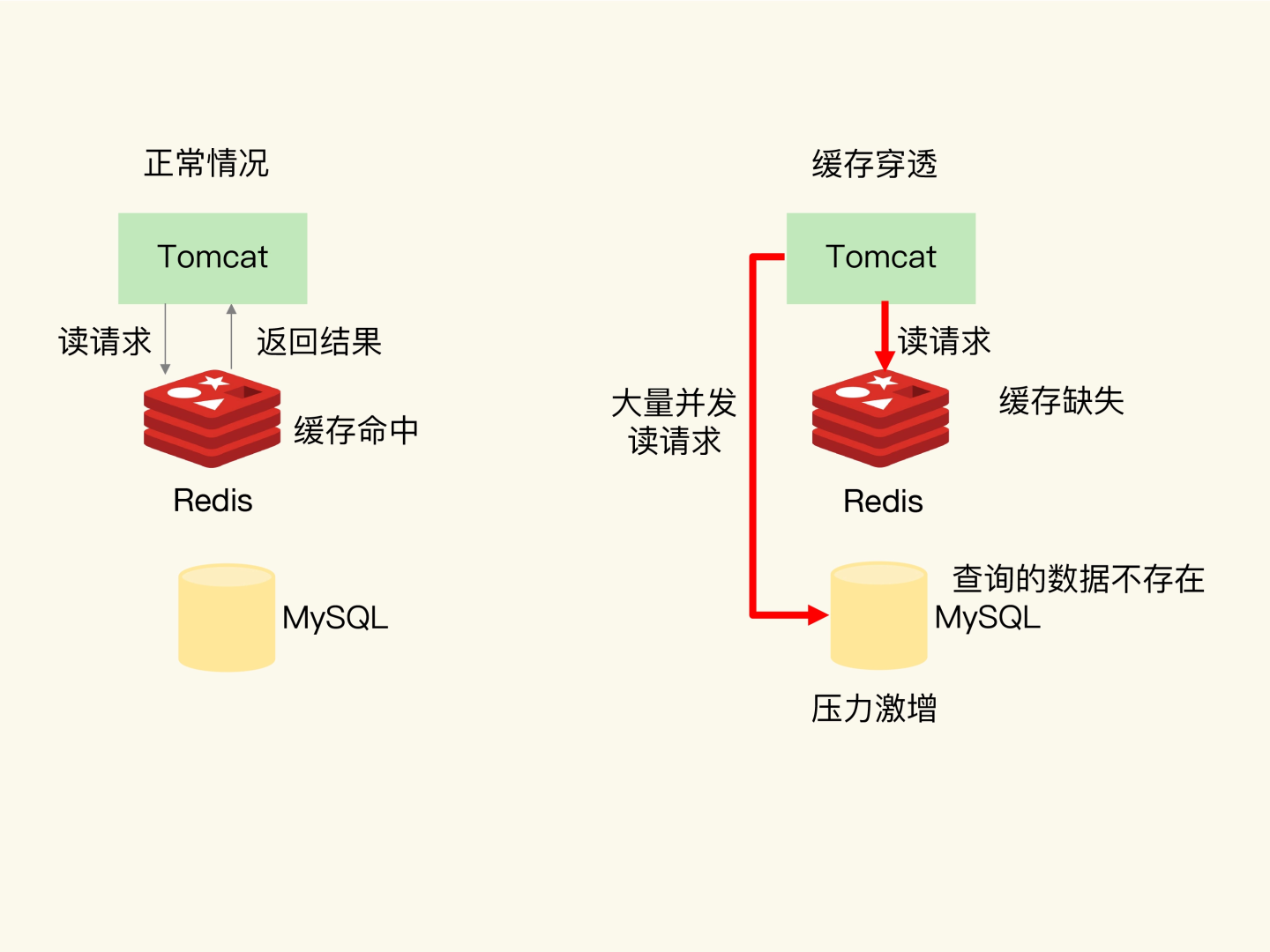
解决方案
- 接口增加业务层级的Filter,进行合法校验,这可以有效拦截大部分不合法的请求。
- 作为第一点的补充,最常见的是使用布隆过滤器,针对一个或者多个维度,把可能存在的数据值hash到bitmap中,bitmap证明该数据不存在则该数据一定不存在,但是bitmap证明该数据存在也只能是可能存在,因为不同的数值hash到的bit位很有可能是一样的,hash冲突会导致误判,多个hash方法也只能是降低冲突的概率,无法做到避免。
- 另外一个常见的方法,则是针对数据库与缓存都没有的数据,对空的结果进行缓存,但是过期时间设置得较短,一般五分钟内。而这种数据,如果数据库有写入,或者更新,必须同时刷新缓存,否则会导致不一致的问题存在。
缓存冷启动
系统第一次上线启动,或者系统在 redis 故障的情况下重新启动,这时在高并发的场景下就会出现所有的流量都会打到原始数据库上去,导致数据库崩溃
解决方案
- 缓存预热:提前给redis中灌入部分数据,再提供服务
缓存带宽打满
一般情况下,缓存带宽打满的主要原因就是大key,如果一个key的大小为1MB,每秒访问量为1000,那么每秒会产生1000MB的流量。这对于普通千兆网卡的服务器来说是灾难性的。合理的 Key 中 Value 的字节大小,推荐小于10 KB 大key会带来三个问题
- 内存空间不均匀
- 操作耗时,存在阻塞风险
- 网络阻塞,每次获取大key产生的网络流量较大。
解决方案
- 导出rdb文件分析: bgsave, redis-rdb-tool,对key进行缓存维度化拆分,将大key拆分成对个key-value,使用multiGet方法获得值,这样的拆分主要是为了减少单台操作的压力,而是将压力平摊到集群各个实例中,降低单台机器的IO操作。
缓存数据库双写不一致
解决方案
生产使用注意事项
- 所有项目的RedisKey最好有一套统一的规则,不管是在做拦截也好,统计也好,能一眼看出来是哪个应用的key,干什么的key
- 禁止大对象
- 要给key设置过期时间,你存在redis的数据要有自动恢复机制,生产环境如果redis有问题在代码里要是可以自动恢复到redis的