为什么要做内存淘汰?
缓存的空间容量必然要小于后端数据库的数据总量,随着要缓存的数据量越来越大,有限的缓存空间不可避免地会被写满
内存淘汰的步骤有哪些?
- 根据一定的策略,筛选出对应用访问来说“不重要”的数据;
- 将这些数据从缓存中删除,为新来的数据腾出空间
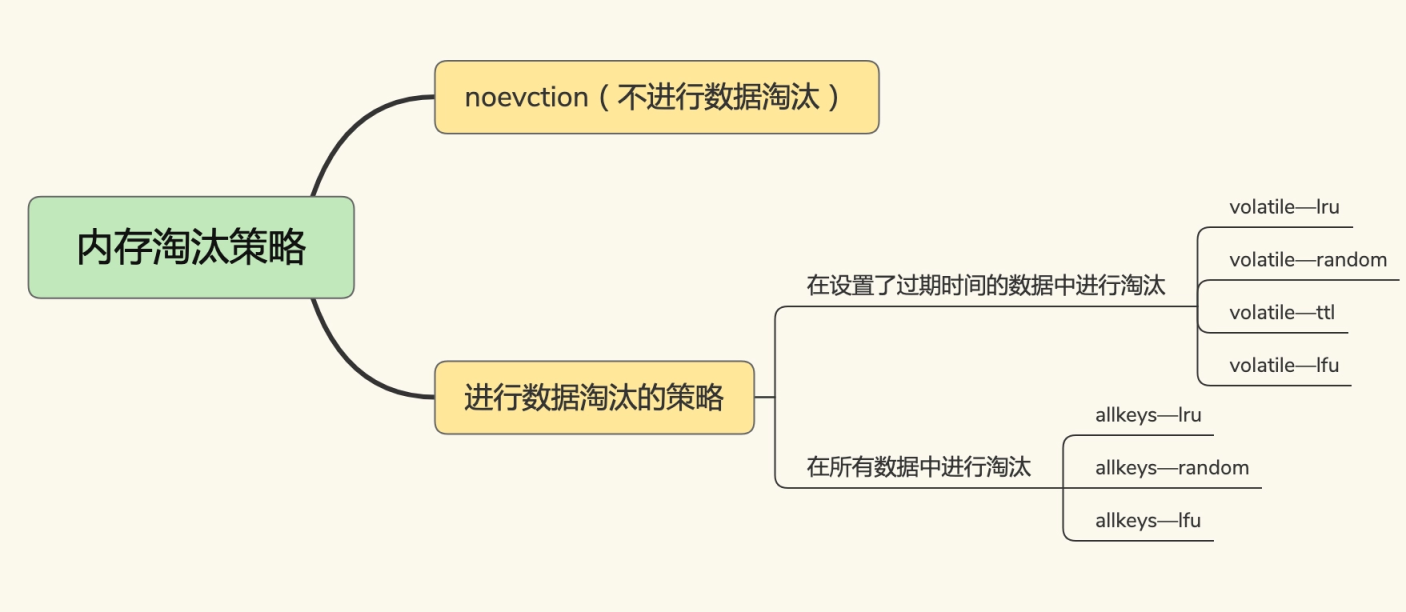
Redis淘汰策略
 在Redis3.0之后的版本默认情况下,Redis 在使用的内存空间超过 maxmemory 值时,并不会淘汰数据,也就是设定的 noeviction 策略。对应到 Redis 缓存,也就是指,一旦缓存被写满了,再有写请求来时,Redis 不再提供服务,而是直接返回错误。
在Redis3.0之后的版本默认情况下,Redis 在使用的内存空间超过 maxmemory 值时,并不会淘汰数据,也就是设定的 noeviction 策略。对应到 Redis 缓存,也就是指,一旦缓存被写满了,再有写请求来时,Redis 不再提供服务,而是直接返回错误。
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除
- volatile-lfu(redis 4新增):从所有配置了过期时间的键中驱逐使用频率最少的键
- allkeys-lfu(redis 4新增):从所有键中驱逐使用频率最少的键
我们在其中看到lru和4.0以后新增的lfu,下面主要介绍LRU算法
LRU (Least Recently Used)
LRU是根据最近最少使用的原则来筛选数据,最不常用的数据会被筛选出来,而最近频繁使用的数据会留在缓存中
LRU 会把所有的数据组织成一个链表,链表的头和尾分别表示 MRU 端和 LRU 端,分别代表最近最常使用的数据和最近最不常用的数据
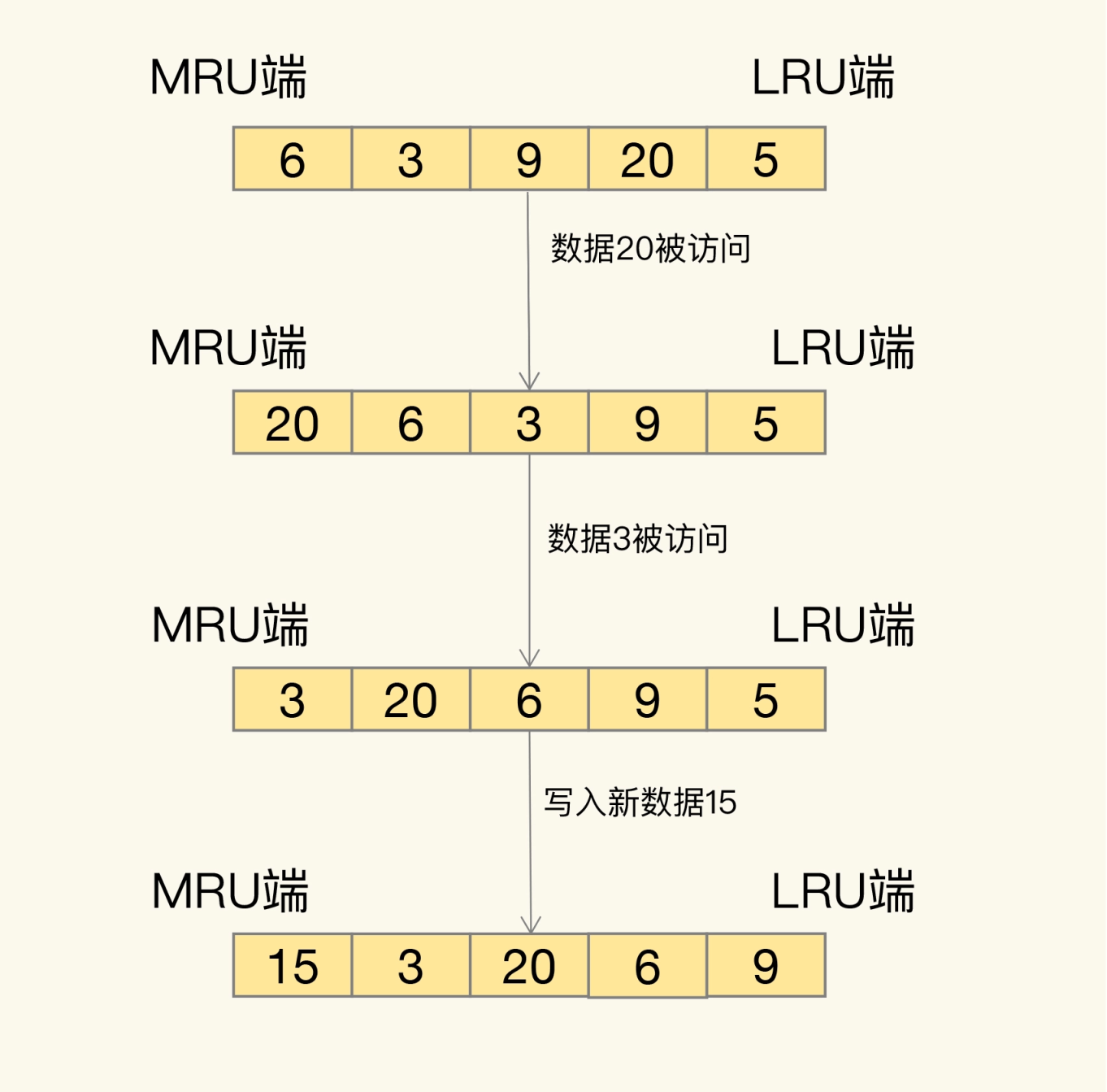 上图写入和访问都算热数据,会被前置到MRU端。
上图写入和访问都算热数据,会被前置到MRU端。
LRU 算法在实际实现时,需要用链表管理所有的缓存数据,这会带来额外的空间开销。而且,当有数据被访问时,需要在链表上把该数据移动到 MRU 端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
Redis3.0中对LRU的优化
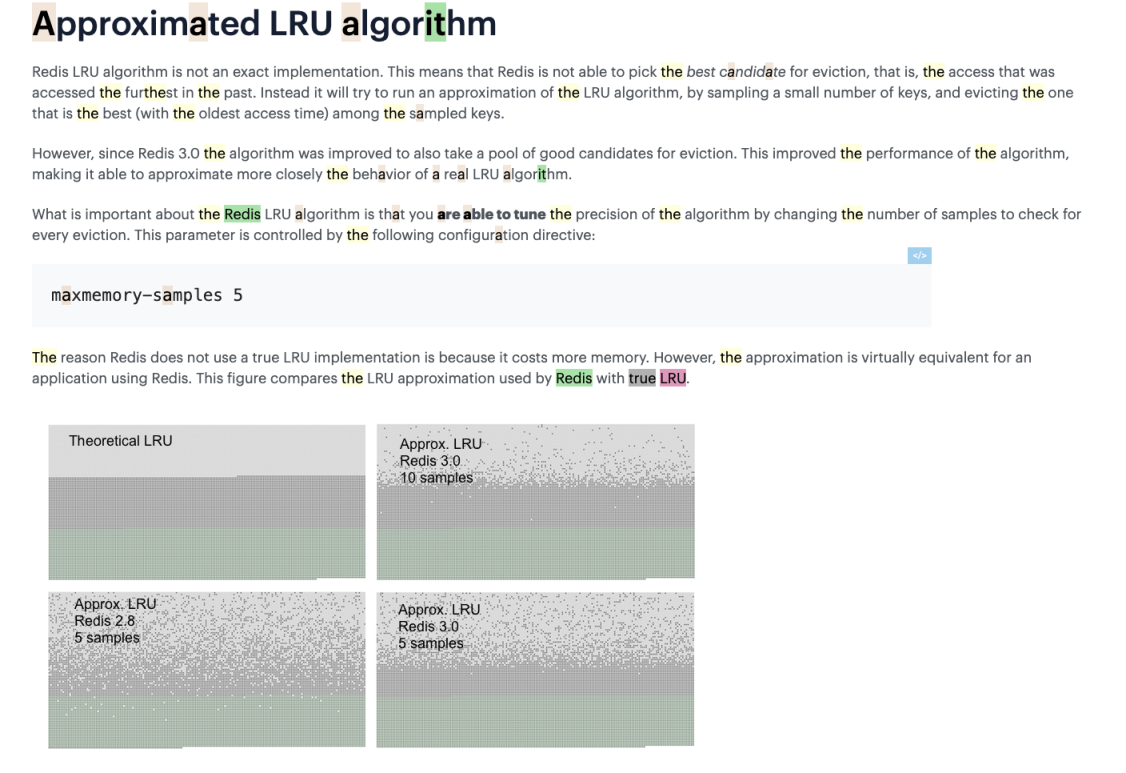 The reason why Redis does not use a true LRU implementation is because it costs more memory.
Redis 没有使用真实的 LRU 算法的原因是因为这会消耗更多的内存。
Redis这次优化给每个key增加了一个额外的小字段,长度为24个bit,用于保存最后一次访问的时间戳。
同时增加了淘汰池,大小是 maxmemory_samples,在每一次淘汰循环中,新的采样出来的key会和淘汰池中的key进行融合,淘汰掉最旧的一个key,然后将剩余最旧的key列表放入淘汰池,等待下次循环。
The reason why Redis does not use a true LRU implementation is because it costs more memory.
Redis 没有使用真实的 LRU 算法的原因是因为这会消耗更多的内存。
Redis这次优化给每个key增加了一个额外的小字段,长度为24个bit,用于保存最后一次访问的时间戳。
同时增加了淘汰池,大小是 maxmemory_samples,在每一次淘汰循环中,新的采样出来的key会和淘汰池中的key进行融合,淘汰掉最旧的一个key,然后将剩余最旧的key列表放入淘汰池,等待下次循环。
Java实现的LRU
其中之一的方法是使用LinkedHashMap这个类,初始化的时候指定容量,重写removeEldestEntry方法判断size即可实现
MySQL中的LRU
LRU 在 MySQL 的应用就是 Buffer Pool,也就是缓冲池,后续文章会有关于缓冲池的内容
如何选择淘汰策略?
- 优先使用 allkeys-lru 策略。这样,可以充分利用 LRU 这一经典缓存算法的优势,把最近最常访问的数据留在缓存中,提升应用的访问性能。
- 如果你的业务数据中有明显的冷热数据区分,我建议你使用 allkeys-lru 策略。如果业务应用中的数据访问频率相差不大,没有明显的冷热数据区分,建议使用 allkeys-random 策略,随机选择淘汰的数据就行。
- 如果你的业务中有置顶的需求,比如置顶新闻、置顶视频,那么,可以使用 volatile-lru 策略,同时不给这些置顶数据设置过期时间。这样一来,这些需要置顶的数据一直不会被删除,而其他数据会在过期时根据 LRU 规则进行筛选。
如何修改淘汰策略?
redis-cli中可以使用info命令查看相应的缓存淘汰策略 可以使用config set maxmemory-policy “allkeys-lfu” 命令修改淘汰策略 config rewrite 配置生效
淘汰对当前请求的延迟问题?
如果此时Redis实例中有存储大key,那么在淘汰大key释放内存时,这个耗时会更加久,延迟更大
如果你的业务访问量非常大,并且必须设置maxmemory限制实例的内存上限,同时面临淘汰key导致延迟增大的的情况,要想缓解这种情况,除了上面说的避免存储大key,也可以考虑拆分实例的方法来缓解,拆分实例可以把一个实例淘汰key的压力分摊到多个实例上,可以在一定程度降低延迟。