为什么要有Partition?
topic是逻辑的概念,partition是物理的概念,对用户来说是透明的。producer只需要关心消息发往哪个topic,而consumer只关心自己订阅哪个topic,并不关心每条消息存于整个集群的哪个broker。 如果topic内的消息只存于一个broker,那这个broker会成为瓶颈,无法做到水平扩展。 所以把topic内的数据分布到整个集群就是一个自然而然的设计方式。 所以Partition就是解决水平扩展的问题
认识Partition
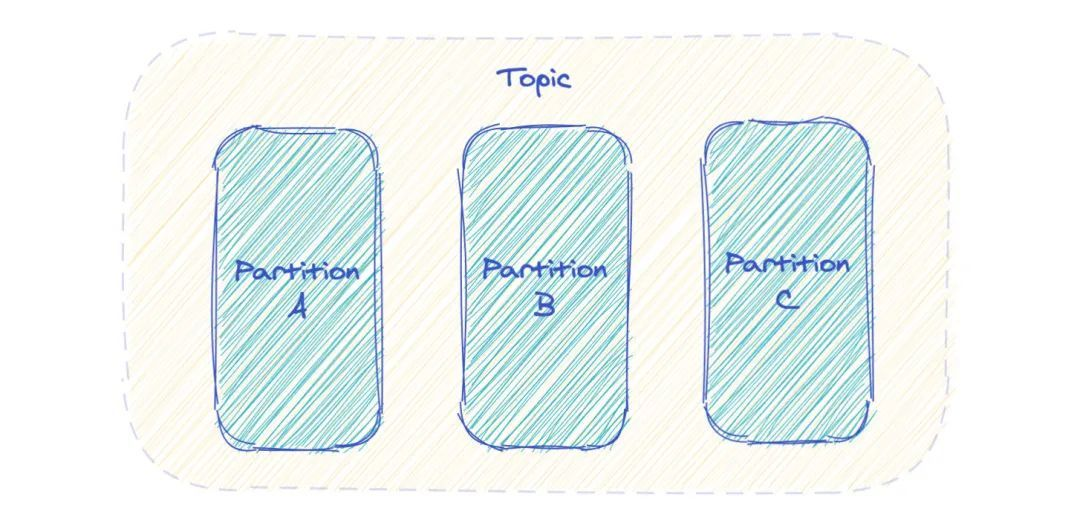 Kafka 中 Topic 被分成多个 Partition 分区。
Topic 是一个逻辑概念,Partition 是最小的存储单元,掌握着一个 Topic 的部分数据。
每个 Partition 都是一个单独的 log 文件,每条记录都以追加的形式写入。
Kafka 中 Topic 被分成多个 Partition 分区。
Topic 是一个逻辑概念,Partition 是最小的存储单元,掌握着一个 Topic 的部分数据。
每个 Partition 都是一个单独的 log 文件,每条记录都以追加的形式写入。
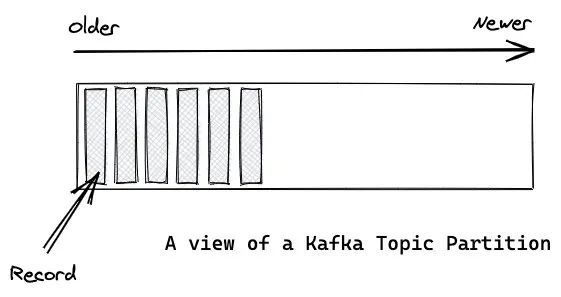
Record(记录) 和 Message(消息)是一个概念。
Partition 中的每条记录都会被分配一个唯一的序号,称为 Offset(偏移量)。 Offset 是一个递增的、不可变的数字,由 Kafka 自动维护。 当一条记录写入 Partition 的时候,它就被追加到 log 文件的末尾,并被分配一个序号,作为 Offset。
为什么不建议设置过多Partition?
1、需要打开更多文件句柄
每个partition在broker的文件系统上都映射着对于的文件夹。 在文件夹里面,每个segment(partition下的存储单位)会有两个文件,一个是索引,另一个是消息数据。 每个broker都会为每个segment打开两个文件句柄。所以如果parition太多的话,你就需要在操作系统里配置下可以同时打开的文件句柄数以使得可以支撑如此之多的segment。曾经见过一个kafka集群,里面的broker平均同时打开了30000多个句柄(约15000个分区),最终可能会突破你的ulimit -n的限制
2、导致可用性降低
一个partition对应着多个副本。在一个broker优雅退出时,集群的controller会提前地将该broker上的leader迁移到其他broker上。 迁移一个leader只需要几毫秒的时间,所以从客户端角度来说,这只会有一小段时间不可用(只在迁移时的时间不可用,毫秒级)
然而如果一台broker是被粗暴的退出了,那不可用时间就取决于partition的数量了。 假设现在有个broker有2000个partition, 每个partition有两个副本,那这个broker大概有1000个leader。 如果这个broker被粗暴退出了,那这1000个partition马上不可用。如果每个分区需要花5ms的时间去选择一个新的leader,则1000个分区需要花费5s。所以,对于其中的partition来说,他们之中最长的不可用时间是5s加上检测出broker挂的时间。 如果更加不幸,这个挂了的broker是集群的controller,那它还需要先在集群里选举一个新的controller后才能进行leader迁移。新的controller还需要从zookeeper(新版kafka已经不从zk里读取)读取metadata。如果一个分区需要2ms,假设一个集群里有10000个partition,那这里将有20s的不可用时间。 建议:一个broker下的partition数量限制在2000-4000,整个集群的partition数量不高于一万。
3、增加了消息的延迟
消息的延迟指的是一条消息从生产者发送到被消费者消费的时间差。 Kafka只会把已经被所有副本复制成功的消息下发给消费者。而kafka的broker只使用单线程去从其他broker里复制消息。 我们实验表明从一个broker复制1000个partition到另一个broker会增加约20ms的延时。 如果复制因子设置为2,那这个问题在一个大集群里不会很明显。 假设现在有一个broker里有1000个leader, 集群里还有另外10个broker。 其他的10个broker平均只需要从第一个broker里获取100个partition的信息,因此,这种情况下的延时就非常小,一般只有几ms。 建议:每个broker下的partition数量应该限制为100br,b是集群里的broker数量,r是复制因子。
4、使得客户端需要占用更多的内存
生产者会给每个partition申请一份内存空间用以缓存将要发送但还没发送的数据。这种批量发送的方式能够减少网络交换次数,提高发送的效率。但如果你的partition太多,则生产者需要更多个内存来缓存将要发送的消息。 消费者也一样,消费者也可以从partition里批量拉取消息,分区越多,则拉取消息占用的内存越多。