信息具备时效性,请在阅读文章的时候对一些缺点优点要保持探索的精神,看一下现在是否支持了这些缺点,或者又强化了哪些优点
概念对齐
Bson
BSON( Binary Serialized Document Format) 是一种二进制形式的存储格式,采用了类似于 C 语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具有轻量性、可遍历性、高效性的特点,可以有效描述非结构化数据和结构化数据。BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。BSON可以做为网络数据交换的一种存储形式,这个有点类似于Google的Protocol Buffer,但是BSON是一种schema-less的存储形式,它的优点是灵活性高,但它的缺点是空间利用率不是很理想,
MongoDB文档"_id"
这是每个MongoDB文档中一定会存在的字段。_id字段表示MongoDB文档中的唯一值。_id字段类似于文档的主键。如果创建的新文档中没有_id字段,MongoDB将自动创建该字段。
集合
这是MongoDB文档的分组。集合等效于在任何其他RDMS(例如Oracle或MS SQL)中创建的表。集合存在于单个数据库中。从介绍中可以看出,集合不强制执行任何结构。
游标
这是指向查询结果集的指针。客户可以遍历游标以检索结果。
数据库
这是像RDMS中那样的集合容器,其中是表的容器。每个数据库在文件系统上都有其自己的文件集。MongoDB服务器可以存储多个数据库。
文档
MongoDB集合中的记录基本上称为文档。文档包含字段名称和值。
字段
文档中的名称/值对。一个文档具有零个或多个字段。字段类似于关系数据库中的列。
基本介绍
特点
(1)面向集合存储,易于存储对象类型的数据 (2)模式自由 (3)支持动态查询 (4)支持完全索引,包含内部对象 (5)支持复制和故障恢复 (6)使用高效的二进制数据存储,包括大型对象(如视频等)
语法入门
基础入门简单带过,详细可以了解MongoDB官方网站
Insert
Query

Update

delete

聚合查询
MongoDB 提供了三种执行聚合的方法:聚合管道、map-reduce和单一目的聚合方法,我们在应用中更多的会使用聚合管道和单一目的聚合方法更多一些。
聚合管道
示例
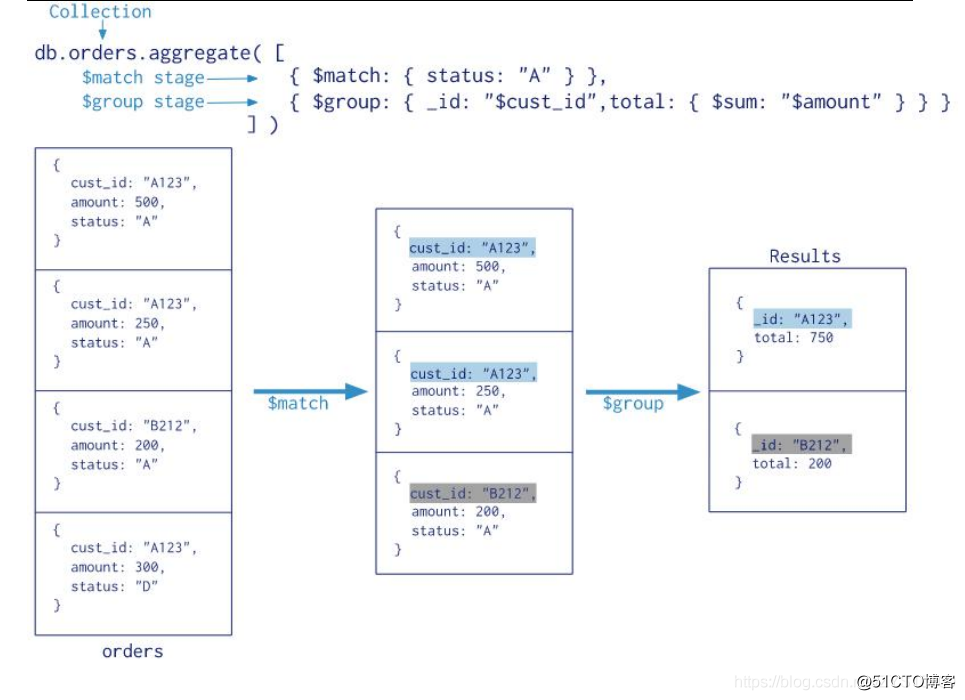
聚合管道是用于数据聚合的框架,其模型基于数据处理管道的概念。文档进入多阶段管道,将文档转换为聚合结果。
第一阶段:$match阶段按status字段过滤文档,并将status等于"A"的文档传递到下一阶段。
第二阶段:$group阶段按cust_id字段将文档分组,以计算每个cust_id唯一值的金额总和。
聚合管道优化
投影优化
聚合管道可以确定它是否仅需要文档中的字段的子集来获得结果。如果是这样,管道将只使用那些必需的字段,减少通过管道的数据量。
管道序列优化
($project or $unset or $addFields or $set) + $match 序列优化
对于包含投影阶段($project或$unset或$addFields或$set)后跟$match阶段的聚合管道,MongoDB 将$match阶段中不需要在投影阶段计算的值的任何过滤器移动到投影前的新$match阶段。 如果聚合管道包含多个投影 and/or $match阶段,MongoDB 会为每个$match阶段执行此优化,将每个$match过滤器移动到过滤器不依赖的所有投影阶段之前。
|
|
优化器将**$match**阶段分成四个单独的过滤器,一个用于$match查询文档中的每个键。然后优化器将每个筛选器移动到尽可能多的投影阶段之前,根据需要创建新的$match阶段。鉴于此示例,优化程序生成以下优化管道:
|
|
$match过滤器{ avgTime: { $gt: 7 } }取决于$project阶段来计算avgTime字段。 $project阶段是此管道中的最后一个投影阶段,因此avgTime上的$match过滤器无法移动。 maxTime和minTime字段在$addFields阶段计算,但不依赖于$project阶段。优化器为这些字段上的过滤器创建了一个新的$match阶段,并将其放在$project阶段之前。 $match过滤器{ name: “Joe Schmoe” }不使用在$project或$addFields阶段计算的任何值,因此它在两个投影阶段之前被移动到新的$match阶段。
[success] 注意 优化后,过滤器{ name: “Joe Schmoe” }位于管道开头的$match阶段。这具有额外的好处,即允许聚合在最初查询集合时在name字段上使用索引
$sort + $match 序列优化
如果序列中带有$sort后跟$match,则$match会移动到$sort之前,以最大程度的减少要排序的对象的数量。例如,如果管道包含以下阶段:
|
|
在优化阶段,优化程序将序列转换为以下内容:
|
|
$redact + $match 序列优化
如果可能,当管道的$redact阶段紧在$match阶段之后时,聚合有时可以在$redact阶段之前添加$match阶段的一部分。如果添加的$match阶段位于管道的开头,则聚合可以使用索引以及查询集合来限制进入管道的文档数 例如,如果管道包含以下阶段:
|
|
优化器可以在$redact阶段之前添加相同的$match阶段:
|
|
$project/ $unset + $skip序列优化
3.2版本中的新功能。 当有一个$project或$unset之后跟有$skip序列时,$skip 会移至$project之前。例如,如果管道包括以下阶段:
|
|
在优化阶段,优化器将序列转换为以下内容:
|
|
管道聚合优化
$sort + $limit合并
Mongodb 4.0版本的改变。 当一个$sort先于$limit,优化器可以聚结$limit到$sort,如果没有中间阶段的修改文件(例如,使用数$unwind,$group)。如果有管道阶段会更改和阶段之间的文档数,则MongoDB将不会合并$limit到 。$sort$sort$limit 例如,如果管道包括以下阶段:
|
|
在优化阶段,优化器将序列合并为以下内容:
|
|
这样,排序操作就可以仅在执行过程中保持最高n结果,这n是指定的限制,MongoDB仅需要将n项目存储在内存中 。 用$skip进行序列优化 如果$skip在$sort 和$limit阶段之间有一个阶段,MongoDB将合并 $limit到该$sort阶段并增加该 $limit值$skip。
$limit+ $limit合并
当$limit紧接着另一个时 $limit,两个阶段可以合并为一个阶段 $limit,其中限制量为两个初始限制量中的较小者。例如,管道包含以下序列:
|
|
然后,第二$limit级可以聚结到第一 $limit阶段,并导致在单个$limit 阶段,即限制量10是两个初始极限的最小100和10。
|
|
$skip+ $skip合并
当$skip紧跟另一个$skip,这两个阶段可合并成一个单一的$skip,其中跳过量为总和的两个初始跳过量。例如,管道包含以下序列:
|
|
然后,第二$skip阶段可以合并到第一 $skip阶段,并导致单个$skip 阶段,其中跳过量7是两个初始限制5和的总和2。
|
|
$match+ $match合并
当一个$match紧随另一个紧随其后时 $match,这两个阶段可以合并为一个单独 $match的条件 $and。例如,管道包含以下序列:
|
|
然后,第二$match阶段可以合并到第一 $match阶段,从而形成一个$match 阶段
|
|
$lookup + $unwind 合并
3.2版中的新功能。 当a $unwind立即紧随其后 $lookup,并且在 领域$unwind运行时,优化程序可以将其合并 到阶段中。这样可以避免创建较大的中间文档。as$lookup$unwind$lookup 例如,管道包含以下序列:
|
|
优化器可以将$unwind阶段合并为 $lookup阶段。如果使用explain 选项运行聚合,则explain输出将显示合并阶段:
|
|
map-reduce
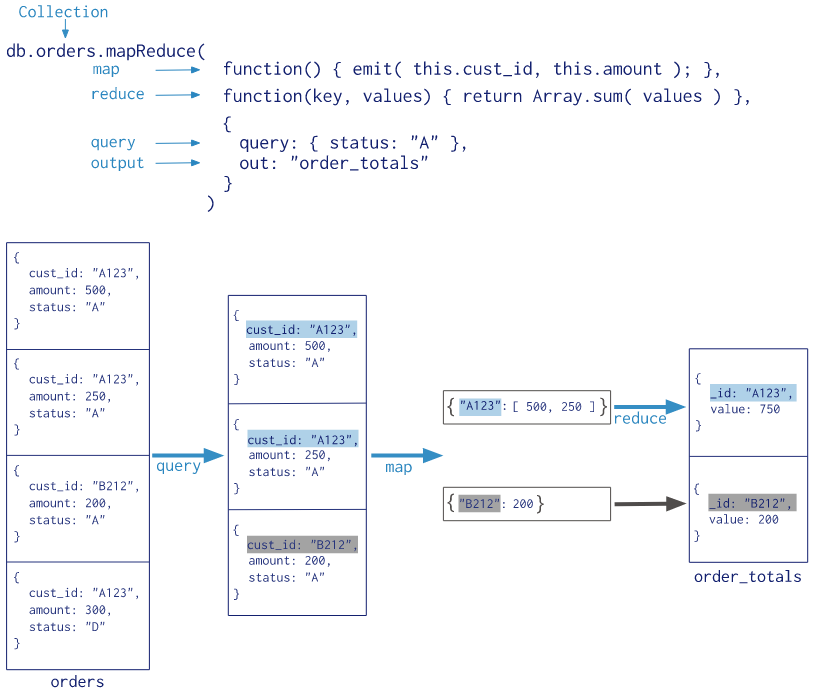
通常,map-reduce 操作有两个阶段:一个 map 阶段,它处理每个文档并为每个输入文档发出一个或多个对象,以及将map操作的输出组合在一起的_reduce_阶段。可选地,map-reduce 可以具有最终化阶段以对结果进行最终修改。与其他聚合操作一样,map-reduce 可以指定查询条件以选择输入文档以及对结果排序和限制。
与聚合管道相比,自定义JavaScript提供了很大的灵活性,但通常情况下,map-reduce比聚合管道效率低,而且更复杂。
单一目的聚合方法
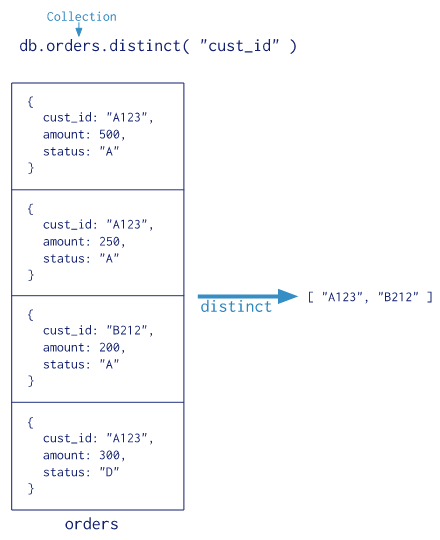
MongoDB 还提供 db.collection.estimatedDocumentCount(), db.collection.count()和db.collection.distinct()。
所有这些操作都聚合来自单个集合的文档。虽然这些操作提供了对常见聚合过程的简单访问,但它们缺乏聚合管道和 map-reduce 的灵活性和功能。